- Published on
The most effective outbox equivalent you can apply on AWS!
Introduction
So you're building distributed systems, maybe dabbling in microservices, and you've hit the classic problem: how do you reliably update your database and publish an event? Atomicity, right? The Outbox pattern probably popped into your head, maybe you've even seen complex implementations involving background workers, polling, and extra tables.
It's often touted as the solution. But what if you're on AWS? What if there's a simpler, more "cloud-native" way that's arguably more scalable and resilient with less fuss? Here's what it's about.
Why the Outbox is so Popular?
In a nutshell, you perform an action, say, processing an Order. You need to save the result to your database (e.g., DynamoDB) and also notify other parts of your system (or external systems) by publishing an event (e.g., to SNS/SQS) that an Order has happened. Doing these two things separately is risky.
What if the database write succeeds, but the event publishing fails? Or vice-versa? You end up with inconsistent state, lost events, or duplicate processing.
The traditional Outbox pattern solves this by writing the event to a dedicated "outbox" table within the same database transaction as the main data. A separate process then reads from this outbox table and reliably publishes the events. It ensures atomicity.
Clever, but it adds complexity: extra tables, polling mechanisms, potential single points of failure or scaling bottlenecks in the writers or polling process.
But wait, we're on AWS!
If you're using DynamoDB, AWS offers a powerful alternative built right into the database: DynamoDB Streams.
Think of it as a Change Data Capture (CDC) mechanism specifically for DynamoDB. When you enable Streams on a table, every change (insert, update, delete) generates an event record. These records flow into a stream that other AWS services, most notably Lambda, can subscribe to.
This unlocks a much simpler architecture:
- Your service writes data to DynamoDB (e.g. an order created event).
- DynamoDB automatically captures this change and puts it into the Stream.
- A Lambda function automatically triggers off the Stream, receives the change event, and handles the "post-commit" logic, like publishing to SNS/SQS or ETL pipelined into another store.
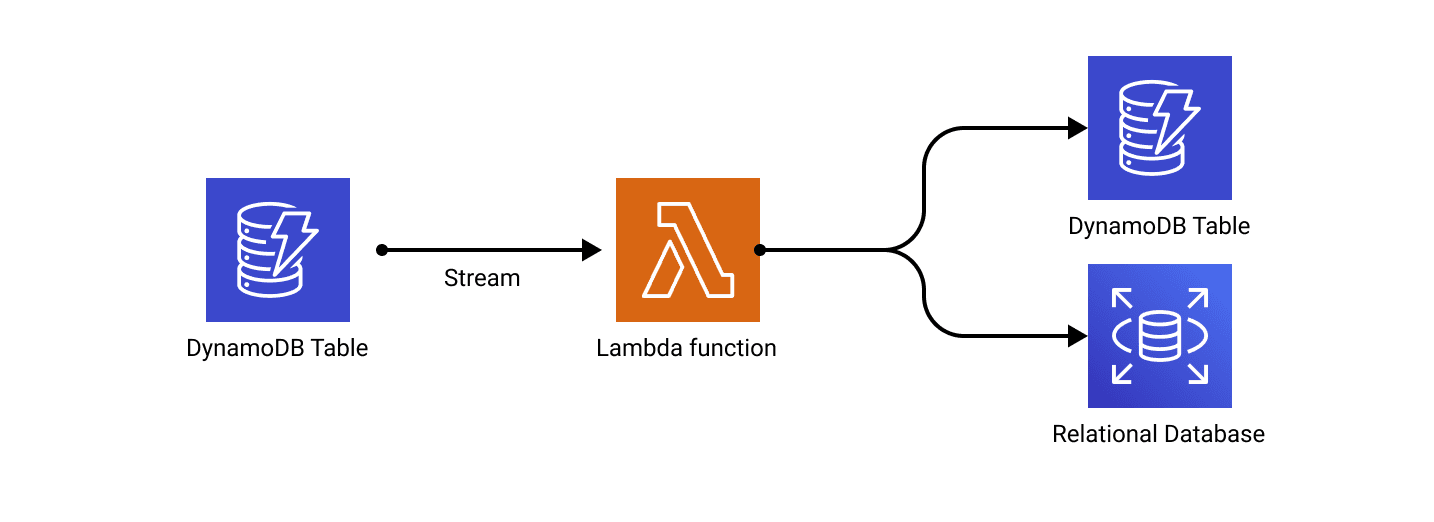
This approach avoids the extra outbox table and the custom polling logic. AWS handles the reliable delivery of change events from the database to your processor (the Lambda).
DynamoDB Streams and CDC to the rescue!
Diving deeper into how this actually works and why it's often a better fit on AWS than a manual Outbox for most cases.
DynamoDB Streams Explained
When you enable DynamoDB Streams on your table, you need to choose what information goes into the stream record for each change. This is the StreamViewType. You have a few options:
KEYS_ONLY: Just the partition and sort key of the changed item. Minimal data.OLD_IMAGE: The entire item as it looked before the change. Useful for rollback logic or tracking deletions.NEW_IMAGE: The entire item as it looks after the change. This is often what you want for triggering downstream actions based on the new state.NEW_AND_OLD_IMAGES: Both the new and old images. Most flexible, but also the largest records. Useful if you need to compare the before/after state directly in your consumer.
NEW_IMAGE is surely the most common one for our use case. AWS then handles the magic. It creates an ordered log of these item-level modifications within shards. Below are the main benefits:
- Simplicity: The setup is minimal. Enable streams on the table, configure a Lambda trigger – that's the core of it. No extra database tables, no complex polling logic to write and maintain.
- Decoupling: Your primary service just writes to DynamoDB. It doesn't need to know how events are published or who consumes them. The Lambda function handles that downstream logic.
- Scalability: DynamoDB Streams scale automatically with your table's throughput. As your write traffic increases, DynamoDB partitions the stream into more shards, allowing for parallel processing by multiple Lambda instances.
By default, this setup is already quite resilient. DynamoDB Streams automatically retry if your Lambda fails, ensuring events aren't easily lost. For many use cases, the default configuration might be perfectly fine to start with!
However, if you're pushing high throughput or have specific reliability needs, understanding the knobs for performance tuning and the nuances of error handling can take your setup to the next level. Let's dive into those details.
(The following sections dive into more advanced configuration for optimizing performance and resilience. Feel free to skip them if the basics cover your needs!)
Resilience: How is this not fragile?
What happens when things go wrong? Your Lambda code might have a bug, a downstream service might be unavailable, etc.
Default DDB Streams Retries: If your Lambda invocation fails (throws an unhandled exception), DynamoDB Streams automatically retries the entire batch of records.
- It keeps retrying for up to 24 hours or until a maximum retry count is hit (
MaximumRetryAttempts). While retrying, DynamoDB Streams pauses processing for that specific shard to preserve order. If one "bad" record causes failures, it can block all subsequent records in that shard for up to 24 hours! This can turn a small bug into a major backlog.
- It keeps retrying for up to 24 hours or until a maximum retry count is hit (
BisectBatchOnFunctionError(Split Batch on Error): This setting helps mitigate the "bad record blocking" problem.True: If a batch fails, DDB Streams splits the batch in half and retries each half separately. This helps isolate the problematic record(s) faster, allowing other records in the original batch to proceed.False: The exact same batch is retried. Almost always set this toTrue. The trade-off is potentially more Lambda invocations during failures, but it drastically improves resilience against poison pills.
Lambda Timeouts: Set a reasonable timeout for your Lambda function.
- Too high: A stuck function could run for a long time, wasting resources and delaying retries.
- Too low: Legitimate processing, especially with large batches, might get terminated prematurely, leading to unnecessary retries. Measure your P99 processing time for a max-size batch and add a buffer. 5-30 seconds is often a reasonable starting range, depending on the work done.
⚠️ Don't set your Lambda timeout too high or too low. Measure how long your function actually takes with a full batch, add a safety margin, and set the timeout there. Too low causes needless retries; too high can hide problems or waste money if a function hangs.
Handling Non-Transient Errors
The default retry mechanism is great for transient issues (network blips, temporary downstream throttling). But what about permanent errors (e.g., a malformed event your code can never parse due to a bug)? Relying on DDB Streams retries here is dangerous due to the shard-blocking issue.
You probably don't want to block/delay all your events because of a bug affecting a single or subset of events!
You might also want to have more visibility or control on when the retry mechanism (which event to retry, when to retry etc...)
- The Better Way: Implement a
try-catchwithin your Lambda handler. If you encounter an error you know is non-transient (like a parsing error):- Catch the exception.
- Send the specific failing record(s) to a separate SQS Dead-Letter Queue (DLQ).
- Return successfully from the Lambda invocation (or at least filter out the bad records before throwing an exception if other records in the batch were processed).
- Configure alerts on the DLQ size.
- Benefits:
- The DDB Stream thinks the batch (or part of it) succeeded, so the shard doesn't get blocked.
- You have isolated the problematic records in a queue you control.
- You get visibility and can inspect the failed messages.
- You can selectively redrive messages to unblock more critical flows/use cases.
- You can fix the bug and manually redrive the messages from the DLQ (using SQS console or APIs) back to the same Lambda (configure the Lambda to also accept SQS events) or a dedicated processor.
- Configure the DLQ message retention appropriately (e.g., up to 14 days).
- The Better Way: Implement a
Note that your Lambda can still crash before your catch block (e.g., runtime crash, timeout), you still fall back to the DDB Streams retry behavior.
This strategy primarily handles errors within your application logic and non transient issues, rather than the ones covered above.
Advanced Performance Tuning
Okay, it's simple, but is it fast and scalable enough? Yes, if you configure it right. Lambda triggers for DynamoDB Streams have key knobs you need to understand:
Batch Size: Possibly the most important Trigger Config. This controls the maximum number of records pulled from the stream in a single batch and sent to one Lambda invocation.- A smaller batch size (e.g., 5 or 10) means more Lambda invocations for the same number of stream records. Good for lower latency per record processing, but potentially higher concurrency and cost.
- A larger batch size (e.g., 100 or 1000) means fewer Lambda invocations, potentially lower cost, but each invocation takes longer and handles more records. Be mindful of Lambda timeouts and memory limits. If one record in a large batch fails, it can affect the whole batch (more on retries later). Start big (e.g., 100) and increase/decrease based on observed performance and cost.
⚠️ Picking the right batch size is a balancing act. Starting large (like 100 or even 1000) can be more cost-effective as you pay per invocation.
Always watch your function duration and memory use! Tune it down if you hit limits or if processing individual records quickly is more important than batch throughput.
MaximumConcurrency/ParallelizationFactor: This configures how many Lambda instances can concurrently process records from the same stream shard. It ranges from 1 to 10.1: Strict in-order processing per shard. Only one Lambda invocation processes records from a specific shard at any given time.10: Allows up to 10 Lambda invocations to process records from the same shard concurrently. This significantly increases throughput but sacrifices strict ordering within that shard (events from different shards are still processed independently). Increasing this helps parallelism but can lead to out-of-order processing for events related to the same DynamoDB item if they land in the same shard close together. If strict ordering per item is critical, keep this at 1 or implement ordering logic in your consumer. If you mostly care about overall throughput and events are independent, increasing this is beneficial. Be mindful not to overwhelm downstream systems.
If you don't strictly care about per-shard ordering (which you rarely need), start higher (e.g., 10) for better throughput, monitor for throttling or downstream issues.
⚠️ Cranking up the Parallelization Factor (to 10) usually boosts throughput nicely. BUT, you lose strict per-shard ordering. If events for the same item need to be processed strictly in order, which usually aren't, you'll have to keep this at 1.
Optimizing Cold Starts with AOT (.NET specific)
What's a Cold Start?
When a Lambda function hasn't been used recently, AWS needs to initialize a new execution environment: download your code, start the runtime, and then run your handler. This initial setup time is called a "cold start," and it adds latency to the first request(s) after a period of inactivity.
Why does it matter here?
In our DynamoDB Streams setup, Lambda processes events in batches. If traffic is spiky or low, functions might become inactive. When a new batch arrives, a cold start introduces delay before processing begins. For high-throughput or low-latency requirements, minimizing this delay is crucial.
A tiny trick you can do to reduce the occurences of those cold starts is playing with the Provisioned Concurrency, which keeps a specific number of Lambda instances "warm" and ready to process events immediately:
- Reduces cold starts, which can be crucial for latency-sensitive workloads.
- It costs money, as you pay for the time the concurrency is provisioned, even if idle.
- There are account-level limits on total provisioned concurrency, shared across all services. Be a good neighbor! Only use this if you've measured cold starts being a significant problem after other optimizations (like AOT compilation, see below).
⚠️ Only pay for Provisioned Concurrency if you really need it. Measure first! Provisioned Concurrency keeps instances warm, it costs money.
Start with optimizing the runtime itself, for instance using .NET Native AOT (which drastically reduces startup time by pre-compiling code), is often a more cost-effective first step before resorting to provisioned concurrency. Then consider provisioning some concurrency.
(Let me know if you would be interested in a detailed AOT in a writeup!),
Next level Operational Maintenance
What if you need to reprocess/republish events or handle complex failure scenarios? This is very useful in incidents or events migration in general, where you would need to "re-send" an event that already happened before to reconstruct some state downstream!
AWS Step Functions are a quick and easy way to achieve this. You can wire your DLQ to a Step Functions state machine.
This allows for sophisticated retry logic, manual approval steps, or even invoking other Lambdas to modify/correct and republish failed events back to DynamoDB (triggering the stream again).
Great production examples to use
Here's some examples where DynamoDB Streams did save us some code and trouble
- Async Offload: The most common use case. Offload sending emails, generating reports, calling external APIs, updating search indexes (OpenSearch/Elasticsearch) without blocking the main request path.
- Database Migration / Replication: Stream changes from one DynamoDB table to another (perhaps with a different schema) or even to a completely different database type (e.g., replicating to RDS/Aurora via Lambda).
- Event Sourcing / Event Publishing: Use DynamoDB as an event store, and the stream reliably publishes these domain/integration events to other teams/systems.
- Integrating External Systems: Use the Lambda as an Anti-Corruption Layer. It can throttle calls to external APIs (using Lambda's concurrency controls), transform data formats, and handle external system outages gracefully via the DLQ.
- Republishing / Event Migration: The Step Functions integration allows powerful reprocessing and event migration workflows.
Well I still want to be trendy and use an Outbox...
Okay, sometimes the traditional Outbox pattern is the right choice, especially if:
- You're not on AWS or not using DynamoDB.
- You need absolute guaranteed ordering, exactly once delivery across all events, and the DDB Streams per-shard ordering isn't sufficient.
- You're already using an ORM like Entity Framework Core in a relational database context, where frameworks like MassTransit offer mature Outbox implementations. (See my other article on MassTransit Outbox with EF Core).
- You're already using CDC tools like Debezium with PostgreSQL or other databases.
But for many common AWS/DynamoDB scenarios, the complexity of a manual Outbox is often unnecessary overhead compared to the simplicity, scalability, and resilience offered by DynamoDB Streams and Lambda.
Ending Notes
Patterns aren't dogma. The "standard" Outbox pattern solves a real problem, but context matters. On AWS, leveraging managed services like DynamoDB Streams and Lambda often provides a more efficient, scalable, and easier-to-manage solution for the same problem.
Before reaching for complex patterns, evaluate the tools your platform provides. Sometimes, the simplest approach is the most effective.
Always experiment, measure, and understand the trade-offs you're making.